
Any developer, SRE or DevOps engineer responsible for an application with users has felt the pain of responding to a high priority incident. There’s the immediate stress of mitigating the issue as quickly as possible, often at odd hours and under severe time pressure. There’s the bigger challenge of identifying root cause so a durable fix can be put in place. There’s the aftermath of postmortems, reviews of your monitoring and observability solutions, and inevitable updates to alert rules. And there’s the typical frustration of wondering what could have been done to avoid the problem in the first place.
In a modern cloud native environment, the complexity of distributed applications and the pace of change make all of this ever harder. Fortunately, AI and ML technologies can help with these human-driven processes. Here are three specific ways:
1. Drastically cut incident remediation times
The toughest incidents are ones where the symptoms are obvious, but the root cause is not. In other words, they are easy to detect, but hard to root cause – as seen in recent outages at GCP, Slack and Snowflake. SREs and engineers can spend hours digging through dashboards, traces, and inevitably – scan millions of log lines. There might be clues to narrow the scope of the problem – perhaps a set of services, containers, or hosts – but ultimately there is a search for the unknown. Is there a new type of error? Or any unusual events? Or a significant deviation from the normal in event patterns? And when there are many of the above – how do they relate to each other?
millions of log lines. There might be clues to narrow the scope of the problem – perhaps a set of services, containers, or hosts – but ultimately there is a search for the unknown. Is there a new type of error? Or any unusual events? Or a significant deviation from the normal in event patterns? And when there are many of the above – how do they relate to each other?
Really experienced engineers develop instincts to help with this hunt for the unknown. But machine learning is very well suited to this problem – it can keep tracking the evolving (but healthy) event patterns and their correlations, quickly surface unusual ones that explain root cause, and even summarize the problem in plain language by matching the events against known problems in the public domain.
2. Eliminate the Alert Rule hamster wheel
The second pain point is the need to revise and continually evolve alert rules and settings that give you early warning. While a pure approach might only monitor a narrow set of user-impacting health metrics and symptoms, that can make it harder to identify root cause. So in reality most organizations set alerts for a blend of user facing symptoms as well as underlying health indicators (errors, latencies, reconnects, resource exhaustion etc.) After a particularly painful incident, it is natural to review and modify alerts – adding new ones or modifying thresholds each time a new type of issue is encountered. The challenge is that as long as new types of problems continue to occur, this is a never ending game of catch up.
and symptoms, that can make it harder to identify root cause. So in reality most organizations set alerts for a blend of user facing symptoms as well as underlying health indicators (errors, latencies, reconnects, resource exhaustion etc.) After a particularly painful incident, it is natural to review and modify alerts – adding new ones or modifying thresholds each time a new type of issue is encountered. The challenge is that as long as new types of problems continue to occur, this is a never ending game of catch up. 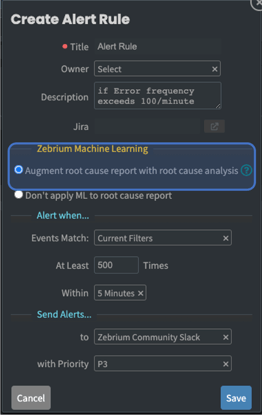
Machine learning can reduce this burden considerably. The simplest approach is to configure a set of “signals” which will trigger ML driven reports. Signals could of course be real incidents, but they could also be symptom alerts. For example, many teams watch for the overall error frequency – if it spikes relative to recent trends, you know something is wrong, but not necessarily what. Well, you can use the same simple alert as a trigger for machine learning to scan the logs and metrics for that deployment around the time of the alert – identifying unusual events/sequences and anomalous metrics that could explain the spike in errors. Even better, machine learning can fingerprint these sequences – so when a particularly noteworthy root cause is detected, you already have a pre-built alert rule you can simply connect to an alert channel.
3. Proactively catch silent bugs and inform developers early in the cycle
In the not too distant past, new releases were tested extensively before deploying to production. This allowed for deliberately constructed test plans, stress tests and an opportunity to catch bugs that might have potentially nasty downstream consequences. Today, deployment cycles are much faster, drastically shrinking the time to do any of the above. There is now a trend towards “test in production”. Although many teams do use staging environments and approaches like chaos tools, it’s more likely that subtle bugs will only surface in production when they result in user complaints or visible symptoms.
have potentially nasty downstream consequences. Today, deployment cycles are much faster, drastically shrinking the time to do any of the above. There is now a trend towards “test in production”. Although many teams do use staging environments and approaches like chaos tools, it’s more likely that subtle bugs will only surface in production when they result in user complaints or visible symptoms.
By using ML to surface new or unusual errors, event patterns and patterns in the metrics, machine learning can quickly become a developer’s best friend in proactively surfacing subtle bugs early, before they impact users. For instance, using our own ML technology, the Zebrium engineering team recently caught a bug related to a malformed middleware SQL query, that under certain conditions prevented users from completing their intended workflow. Another example involved an exception that was handled in a try/catch block which emitted an error log message but was otherwise silently breaking outbound webhook notifications. Our developers have come to appreciate the proactive detection from our internal Zebrium service to catch these kinds of bugs early, before they can do real damage.
Conclusion
As more users rely on software applications, the pressure to shrink MTTR and the stress of troubleshooting incidents under pressure all grow proportionally. Over the last decade a rich set of observability tools have emerged to help detect problems easily, but troubleshooting has remained very manual, driven by the instincts and experience of the engineer on call. New approaches that apply machine learning to tackle this problem can help by drastically reducing MTTR, catching new bugs early, and reducing the manual effort involved in tasks like creating RCA reports and maintaining alert rules.

