
We structure machine data at scale
Zebrium helps dev and test engineers find hidden issues in tests that “pass”, find root-cause faster than ever, and validate builds with self-maintaining problem signatures. We ingest, structure, and auto-analyze machine data - logs, stats, and config - collected from test runs. We create and load a relational database you can query, and we support all use cases from that platform. Our ML pipeline not only structures your data into tables (with columns for the variables), it does anomaly detection that actually works, and keeps your schema and signatures up-to-date since the logged format of a given event might change over time.
Some folks have asked me, why bother structuring the data at all? What does structure do for the user? This blog entry is mostly for them. I want more folks to understand the value of structure, and to be able to recognize at least some of the benefits of using a relational database for structured data.
If you don’t structure up-front, you’ll have to do it later
If you’re querying unstructured data, you perform a structuring operation manually every time you query it. Writing a regex, for example, you might ask yourself a question like, “what are all the possible formats of this token?”, so your regex can work. The same goes for writing a script.
If only a few people know answers to questions like these, there’s a manual bottleneck for querying the data. If no one knows the answers, like when the data format might have changed recently, then someone needs to go data wrangling before a new query... again, a manual bottleneck. When there’s a support case waiting on the answer, no one wants to be the manual bottleneck.
Relational databases are distilled abstraction
RDBMS are so great at abstracting the query interface from structured data, companies can hire sales analysts that aren't salesmen, and BI analysts that aren't programmers. Applications like Excel and Tableau are built to visualize and report on the data in a relational database without any a priori understanding of the data.
Need a reporting tool? Don’t build one for your proprietary stack, use one of many off-the-shelf tools. Need a new report? Type a SELECT statement... or better yet, let your BI team handle it themselves... no programming required.
The relational, SQL-compliant, ACID database, built on foundational principles from E.F. Codd and Jim Gray, is a wildly successful data platform. It remains the most successful platform ever built for structured data. To understand why, we can examine the concept of a technology platform.
Abstraction makes a technology platform great
Abstraction matters in the real world. You can’t have a great App Store if all your app developers need to know how to query hardware registers or roll their own HTTP client. The price of an app wouldn’t justify the work, and there wouldn’t be enough developers with all the necessary skills to participate.
You can’t have a great data platform if every user needs to know how to write regular expressions or PEG parsers. You can’t have a great data platform if every user needs to know that this number in this file represents the “same thing” as another number in another file, just at a different point in time. We need this to be mostly automatic, if we want real abstraction.
The relational database schema is the ultimate API for structured data
All the details of ACID and predicate logic and relational algebra and so on are important because they offer ways to foolproof the RDBMS abstraction, to generalize it as far as possible. Structure is strategic because RDBMS benefits only apply when the data is structured. The schema, the SQL standard, and structured (i.e., minimally normalized) data are usually all you need to ask and answer a question.
What makes Zebrium different is our approach to dealing with machine data, which is generally unstructured. We use machine learning to structure the data at ingest, loading it into a scale-out MPP relational database. Analysts don’t have to understand all historical permutations of the source data to get an answer; scripts don’t have to extract and structure the data at query time.
Relational databases can scale out now
It used to be that databases were mostly monolithic row stores that couldn’t scale-out so well, so that even if you structured your machine data, it might be difficult to get good query performance. Since Stonebraker’s Vertica, there has been a proliferation of so-called “NewSQL” databases, built around an MPP paradigm. Cloudera’s Impala is an example of an MPP SQL query engine. Nowadays even PostgreSQL, another Stonebraker project, completely open source, can scale both up and out.
The strategic benefits of structure also extend to performance. A true relational column store like Vertica can leverage typed, low cardinality columns to dramatically reduce the on-disk footprint of structured machine data by over 10x through encoding. It can also use structure to improve query times by over 100x through late materialization.
A new world is upon us
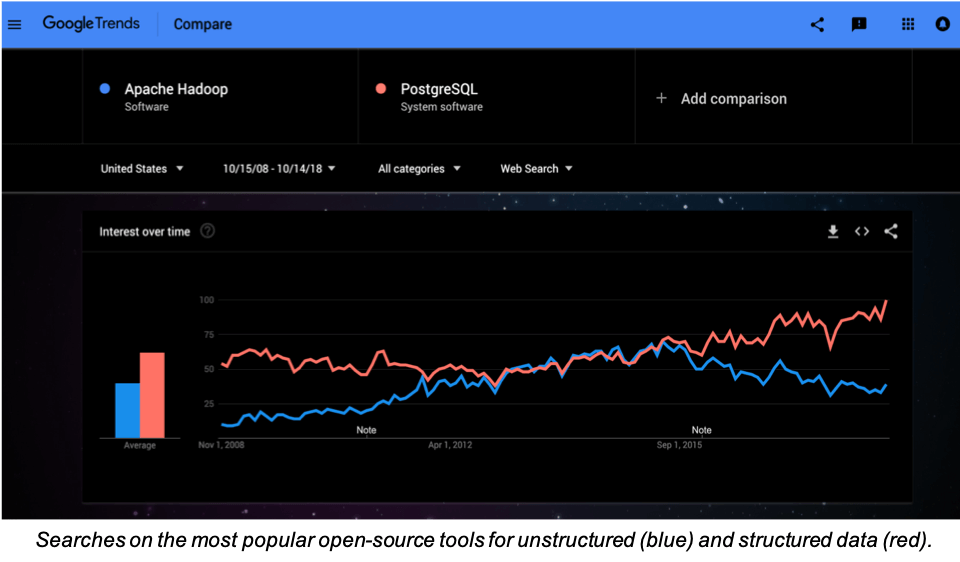
It’s true that folks used to try to get big data tools like Hadoop or indexers like Elastic to perform the role of the database. Those things are built for unstructured data, so until now, they have been state-of-the-art in this space.
What we see more of now is folks incrementally structuring data, then loading it into a relational database for priority queries, often from a Hadoop “data lake”. But once you can structure all the data at ingest, then a whole new world of possibilities and performance opens up.
As the chart at the top shows, folks love structured data in RDBMS for the power it gives them. The days of trying to make do without the RDBMS are coming to a close. The problem for most folks is that they just can’t structure all their data in-advance: structuring is still a manual bottleneck. That’s where Zebrium comes in.
