We're thrilled to announce that Zebrium has been acquired by ScienceLogic!
Learn More

“We were immediately impressed with Zebrium. Within minutes of signing up for our account, the solution uncovered the root cause of a problem that had taken us more than 24 hours to uncover using our legacy observability stack”
Kishan Koduru, Chief Architect, Seagate Lyve Cloud
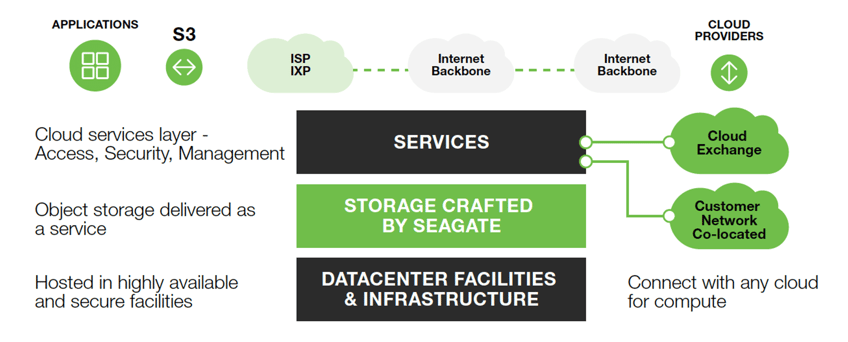
Seagate Lyve™ Cloud is a storage-as-a-service platform that delivers S3-compatible object storage with a simple and predictable cost structure. It offers ultra-high durability and scale along with enterprise grade security and uptime. When it comes to the reliability and resiliency of the Lyve Cloud Service, there are simply no compromises. Prior to release, the software goes through a rigorous testing process that includes unit testing, integration testing, regression testing, system testing, performance testing and endurance testing. During endurance testing, early in the development process, the engineering team uncovered a rare failure mode that took an unacceptably long time to root cause using the existing observability tools. Seagate, therefore, set out to implement a new observability solution that could both catch new software failure modes as early as possible as well as speed up the root cause analysis process.
After a thorough market investigation and a long proof of concept, Seagate selected Zebrium’s machine learning based observability solution. Seagate Lyve Cloud is implemented as a distributed Kubernetes application that is installed across multiple availability zones in key geographic regions around the world. Logs from each environment are sent and analyzed by Zebrium machine learning in near-real time. In addition, the Zebrium platform is integrated with Opsgenie to facilitate a more automated approach to detecting and resolving software incidents.
Lyve Cloud uses a cloud-native microservices architecture and is deployed on Kubernetes clusters. A typical deployment has multiple availability zones, a vast number of nodes and approximately 100 microservices that generate a high volume of logs and metrics per day.
During endurance testing, the Lyve Cloud engineering team uncovered a critical performance issue that affected the object storage service. Using the traditional observability stack that was in place at the time, the problem took over 24 hours to track down. The subtle nature of the problem, in combination with the sheer volume of logs being produced by the environment, meant that engineers had to manually correlate event sequences across multiple log files to piece together what happened.
The Lyve Cloud service is designed to be highly reliable and resilient and is used by mission critical enterprise customers who are extremely sensitive to availability. It therefore became immediately apparent after the long troubleshooting session, that the traditional observability tools that were in place (logging, monitoring and APM) would not be sufficient should a similar kind of issue occur in production.
One of the Lyve Cloud engineers had been researching the topic of Machine Learning for log analysis and was impressed by the Zebrium technology. Based on this, the Lyve Cloud engineering team decided to engage with Zebrium on a formal proof of concept.
Seagate had retained all the logs that were generated at the time of the issue. After signing-up for a Zebrium account, the logs were uploaded into Zebrium. Within minutes, Zebrium had structured the log events and learned their patterns. It also very quickly produced several root cause reports, spanning the period of the logs. It is important to note that there were no pre-configured rules and no pre-training was performed.
There was one report around the time the incident had occurred that immediately caught their eyes. The summary contained two key events that described the problem. With one click, they reviewed the report details, and it showed the exact root cause. The problem related to a memory exhaustion issue in a misconfigured pod. In the actual root cause report were log lines that described both the root cause and symptoms of the problem. It also pinpointed the time the problem started and the pod in which it occurred.
Seagate continued the POC for several weeks, during which Zebrium uncovered several other potential software service problems that the engineering team was able to resolve prior deploying to production. In addition, Zebrium could consistently identify the root cause of problems that were caused by fault injection. At the time of writing this case study, the Lyve Cloud team was in the process of rolling out Zebrium across three production environments located in three regions around the world.
Seagate is a world leader in data storage and management solutions. In February 2021, Seagate released the Lyve Cloud storage-as-a-service platform, an S3-compatible storage-only cloud. Lyve Cloud enables always-on mass capacity data storage and activation. It is designed as a simple, trusted, and efficient service allowing enterprises to unlock the value of their massive unstructured datasets. Seagate is collaborating with Equinix, the world’s digital infrastructure company, to make Lyve Cloud accessible to more customers. This collaboration will provide extensive interconnect opportunities for additional cloud services and geographical expansion.
![]()
![]()