We're thrilled to announce that Zebrium has been acquired by ScienceLogic!
Learn More


Humans troubleshoot software problems by hunting through logs, looking for errors and unexpected events.
Let our machine learning do this for you by finding correlated anomalies in your logs, and turning them into simple to understand root cause reports.


"The order failed because the system was running out of memory."
We use Generative AI to construct simple to understand root cause summaries.


![]()
When a problem occurs and an incident is created in PagerDuty, Opsgenie or Slack, Zebrium will automatically update the open incident with a root cause report.


.png?width=269&name=Zebrium%20is%20SOC%202%20Type%201%20Certified%20(1).png)
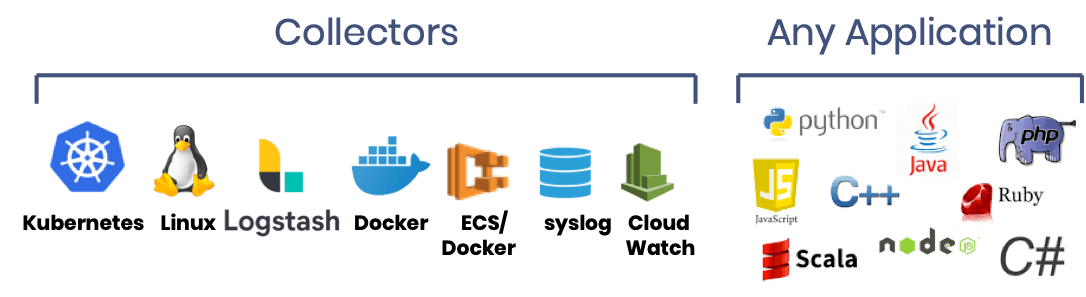
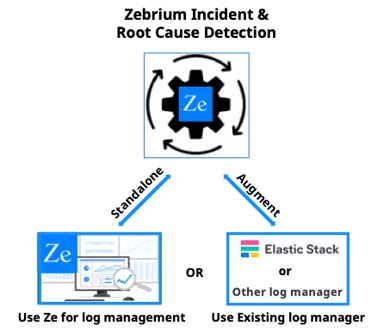
A CLI is also provided to upload individual log files. VMware, Windows and other common platforms available by using our Logstash integration.
Get started in just a few minutes by installing our log collector or using a Logstash output plugin. For best results, please induce an app failure or you won't be able to experience automated root cause analysis. If you can't do that, try it with a sample microservices demo app.
![]()
![]()


