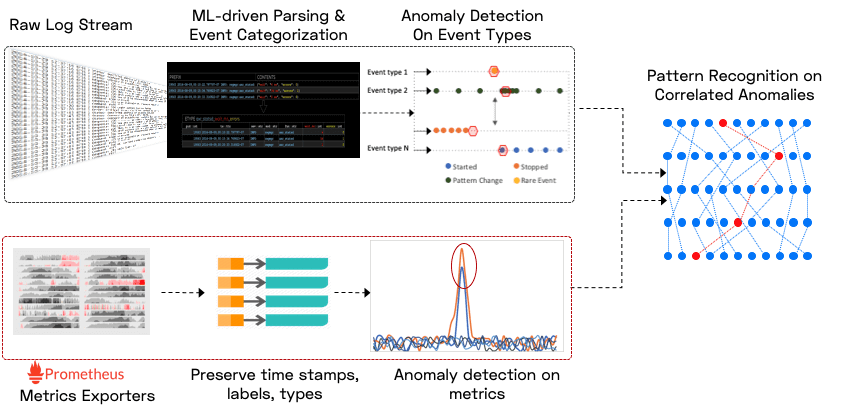
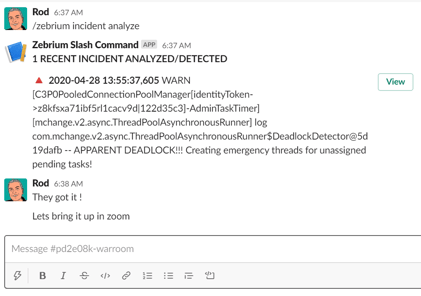
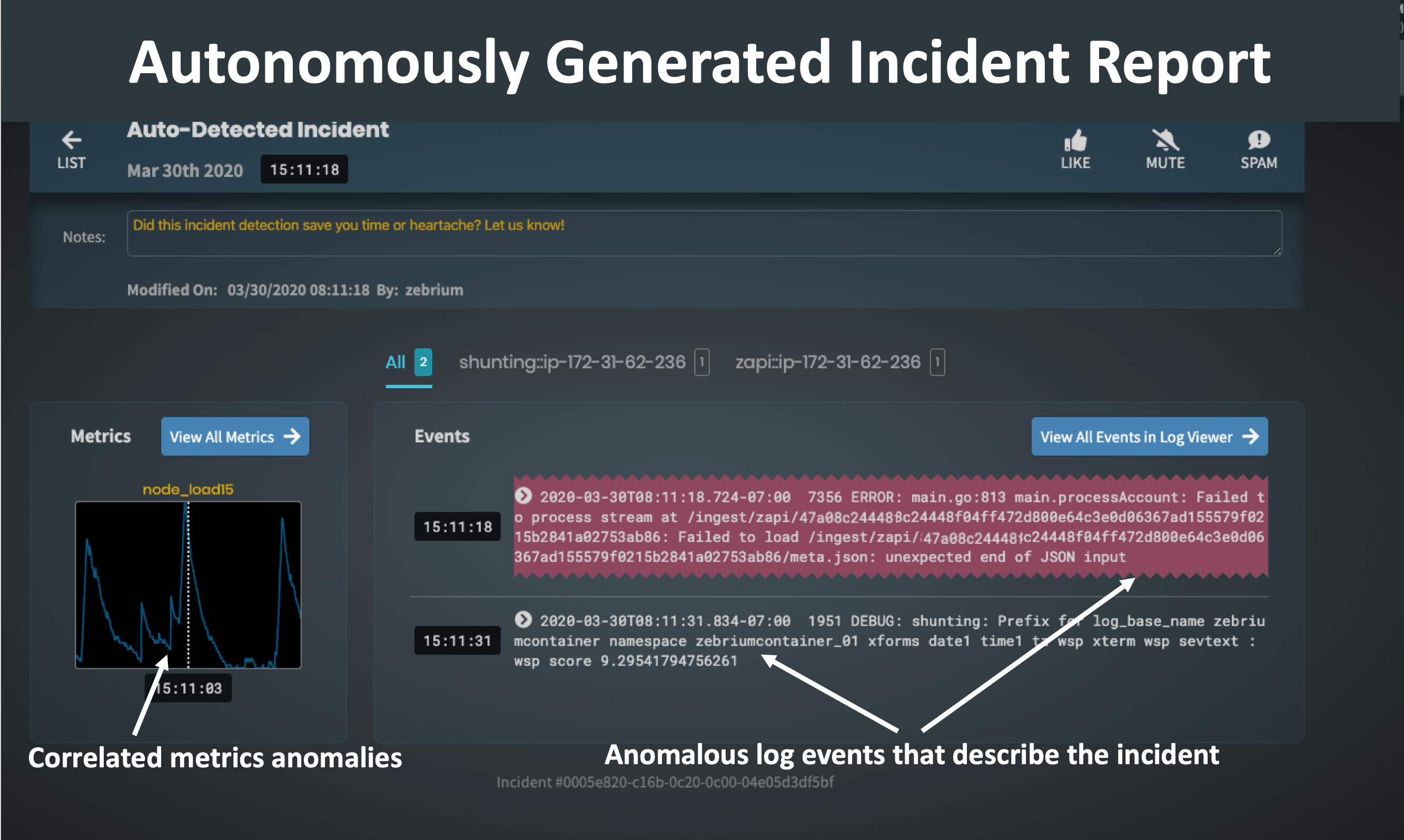
Step 3 - Augment (optional)
If you use an Incident Management tool like PagerDuty, Opsgenie or Slack, or an existing log management or monitoring tool, Zebrium can augment any incident with a characterization of root cause.
A signal is sent to Zebrium when an incident occurs. Or you can trigger a signal from the Zebrium UI. Zebrium then finds any root cause reports or sets of anomalous log/metric patterns that coincide with the signal, and automatically feeds the information back to your incident management tool.
Read more here: You've Nailed Incident detection, what about Incident Resolution.