Application monitoring is experiencing a sea-change. You can feel it as vendors rush to include the phrase "root-cause" in their marketing boilerplate. Common solutions enhance telemetry collection and streamline workflows, but that's not enough anymore. Autonomous troubleshooting is becoming a critical (but largely absent) capability for meeting SLOs, while at the same time it is becoming practical to attempt. This profound transformation is the inevitable consequence of a few clear trends:
1.) Per-Incident Economics (the Motive) - Production incidents capable of impacting thousands of users in a short period of time are now commonplace. It's not enough anymore just to automate incident response based on lessons learned from the first occurrence of a new kind of problem, as was common in the shrink-wrap era, since the first occurrence alone can be devastating. These economics provide the motive for automating the troubleshooting step.
2.) Analytic Technologies (the Means) - It used to be cost- and effort-prohibitive to characterize and correlate metric, trace and log data, at scale, and in near-real-time. Ubiquitous access to fast storage and networks, as well as steady development of OLAP technologies and unsupervised learning algorithms, give us the means to address gaps with automation.
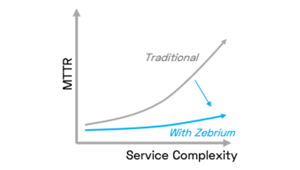
3.) The Troubleshooting Bottleneck (the Opportunity) - Runtime complexity (C) and operational data volume (V) continue to grow. The human eyeball is the bottleneck for troubleshooting, and it doesn't scale. As C and V grow linearly, MTTR for new/unknown/complex issues grows quadratically (~CV). This burgeoning time sink gives us the opportunity to tangibly improve troubleshooting with automation, and with ever-growing benefits into the future.
Root Cause as a Service (RCaaS)
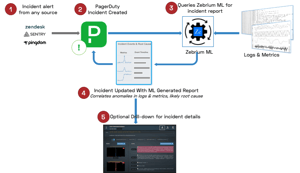
Because of these trends, we believe it's time for a generally useful, generally applicable RCaaS tool, and we believe we have built one. Zebrium delivers RCaaS, and here's what we mean by that: It’s proven (we’ll explain this later) and it delivers a fast-and-easy RCA experience, wherever and however you want it.
We believe that an autonomous troubleshooting tool should work in the general case, out of the box, stand-alone or in tandem with any other observability vendors' tools, and without exotic requirements (rules, training, etc.). The solution should be agnostic to observability stack or ingest method, and it shouldn't make assumptions about what stack you run or how you run it.
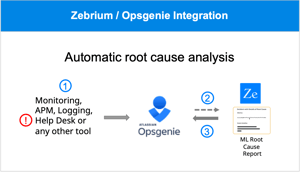
We've Started with Logs
In any journey, you have to start somewhere. The founder of a well-known tracing company once said: "metrics give you when; traces give you where; logs give you why (the root cause)". It's not always true but, as a rule-of-thumb, it's not bad. Here's another, universally-heard rule-of-thumb: digging through logs to root-cause a new, unknown issue is one of the most dreaded experiences in DevOps today.
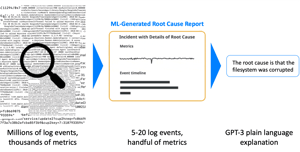
We believe if it has to do one thing well, an autonomous troubleshooting tool should find the same root-cause indicators from the logs that you were going to have to dig to find yourself. The solution should have first-class support for generic and unstructured logs, and it shouldn't require any parsers / alert rules / connectors / training / other configuration to work well.
We've Done the Hard Stuff
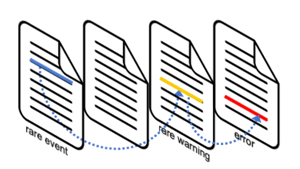
Supporting generic, unstructured logs by inferring their types and parameters correctly behind-the-scenes, is hard. Learning metadata from scratch, at ingest, custom to a particular deployment, is hard. Correlating anomalies across log streams to formulate RC reports, is hard. Summarizing such reports, is hard. These are all incredibly hard problems - but they were, in our view, necessary to accomplish generally useful, autonomous troubleshooting.
Why You Should Trust Us
Vendors have ruined the playing field by hyping "AI" / "ML" tools that don't work very well. Why should you trust that our tool can add value? Well, vendors generally don't present large-scale, quantitative, third-party studies of their tools' effectiveness in real-world scenarios across multiple stacks. We believe such studies are important criteria for buyers selecting tools, and we have such results to share with you.
Cisco Systems wanted to know if they could trust the Zebrium platform before licensing it. They ran a multi-month study of 192 customer incidents across 4 very different product lines (such as Webex client and UCS server, among others). These incidents were chosen because they were the most difficult to root-cause, because they were solved by the most senior engineers, and because their root-cause was inferable from the logs.
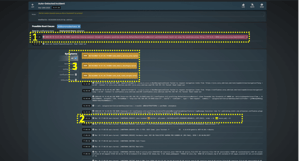
Cisco found that Zebrium created a report at the right time, with the right root-cause indicators from the logs, over 95% of the time. You can read more details about this study here.
Aside from them, we have many satisfied customers, from petascale SaaS companies deploying into multiple GEOs with K8s, to MSPs monitoring windows farms, to enterprises troubleshooting massive production database applications.
Come on this Journey with Us
We've built something very special here. We're not trying to bamboozle you. We have real evidence from the real world that shows our tech works. We've built the first credible, accurate, third-party-proven tool that autonomously delivers root-cause from logs to the dashboard.
Want to run Zebrium in the cloud? We can do that. Want to run it on-prem? Our stack can be deployed on-prem with a chart. Want to monitor a modern cloud-native K8s environment? We have a chart for that too, and customers running K8s clusters with hundreds of nodes in multiple GEOs. We also support ingest via Fluentd, Logstash, Cloudwatch, Syslog, API and CLI, and we’re happy to expand our offerings to support our customers’ needs.
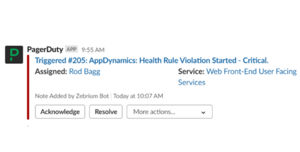
With support for dashboards from Datadog, New Relic, Dynatrace, Elastic/Kibana, Grafana, ScienceLogic, and AppDynamics, we’ll get you up-and-running with autonomous RCA feeding right into your existing monitoring workflow.
Sign up for a free trial from https://www.zebrium.com, or send us an email at hello@zebrium.com to arrange a purchase or PoC.