
Why understand log structure at all?
Software log messages are potential goldmines of information, but their lack of explicit structure makes them difficult to programmatically analyze. Tasks as common as accessing (or creating an alert on) a metric in a log message require carefully crafted regexes that can easily capture the wrong data by accident (or break silently because of changing log formats across software versions). But there’s an even bigger prize buried within logs – the possibility of using event patterns to learn what’s normal and what’s anomalous. However, without understanding log structure, learning normal, and uncovering anomalous patterns are likely to be noisy and unreliable.
The Zebrium platform uses machine learning to autonomously learn the implicit structure of log messages. It cleanly organizes the content of each event type into tables with typed columns – perfect for fast and rich queries, reliable alerts, fault signatures, and high quality pattern learning and anomaly detection.
In the real world, the explicit structure evolves organically
As revolutionary as autonomous structuring is even on a static set of logs, in the real world, logs are fundamentally dynamic. In this context any learned log structures can become obsolete rapidly. For this reason, the Zebrium platform continually updates its learned structures as new instances of events are observed. This is done by paying careful attention to the variable content of each message type and ensuring that it is considered as part of the correct set of content when determining structure. To make this concept more concrete, here is an example of the log learned log structure over time.
A concrete example of log learning over time
Let’s imagine some log lines are being fed into the Zebrium system. New variations of the same message type will be seen over time.
Initial Learned Structure
Let’s look at a specific example - here are a couple of log lines:
 Seeing this line in a sample of other lines, our system initially learns this as a single event type, and extracts the following elements as parameters:
Seeing this line in a sample of other lines, our system initially learns this as a single event type, and extracts the following elements as parameters:

First Structure Adaptation: Introducing a New Variable
As more messages come in, new similar events are observed that a human would think of as the “same type” but that do not match the above representation precisely. Here is an example:

In this case the message is visibly like the previous – except now the word “GET” has changed to “POST”. Our system recognizes this as the same event type as before and updates its representation of BOTH to reflect the new variable as its own column.

Second Structure Adaptation: Handling Optional Elements
In a more complex example, we also see instances of this log message where some of the variable elements are missing:

Note that the name (e.g. “jim”) and the second “id-like” field (e.g. “116rwt9”) are missing from these instances. Our algorithms identify this and, most importantly, properly place the variable elements in the correct column with their appropriate partners.

Correctly aligning these variable elements is critical for all downstream use cases – because improper recognition of the column’s content would cause the column to lose its meaning. It may seem subtle – but there are a lot of wrong ways to do this (e.g. left aligning, right aligning, bumping ambiguous content out as a new column) each of which are obviously problematic:
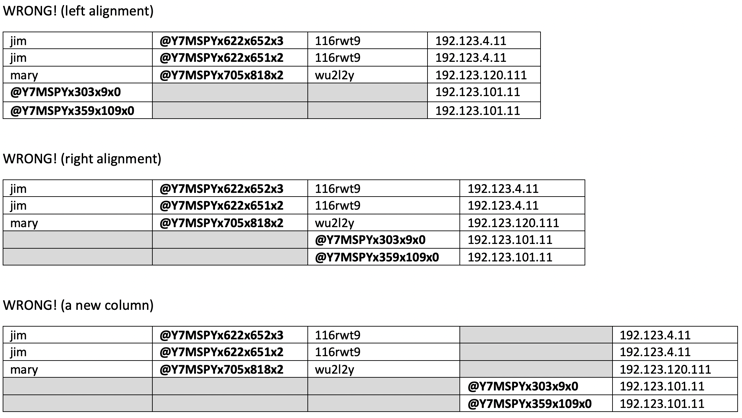
The Zebrium platform recognizes this new content correctly, even though these messages:
- Contain uncommon element types (e.g. these fields are not common elements like integers, IP addresses, file paths etc.)
- Lack any surrounding landmarks for alignment (like conserved punctuation or bracketing)
- Have no 1:1 matches with existing values (I.e. @Y7MSPYx303x9x0 & @Y7MSPYx359x109x0 were not values previously seen in earlier messages)
Precise event types and variables are essential for reliable alerts, signatures and anomaly detection
By autonomously learning this evolving implicit structure of log messages, we can ensure that our anomaly detection and signature matching processes are built on a solid foundation. Without this, the detection of anomalous values in a log message and the faithful recognition of signature matches would be highly error prone. Imagine, for example, a breach where a rogue user shows up in these logs: if the user name field had been contaminated with the much larger cardinality ID (I.e. @Y7MSPYx… as in the “left alignment” example above) such an anomaly would not be detectable due to the noise generated by the frequently changing IDs. Similarly, any fault signatures defined on a misaligned field would behave inconsistently based on which variant of the message was observed.
In conclusion, the reliable programmatic use of logs requires accurate event structuring – while simultaneously requiring that the structure can adapt to ever changing content. The Zebrium platform rises to both these challenges.
If you'd like to try it for yourself, please sign-up for a free account here.
