
The promise of tracing
Distributed tracing is commonly used in Application Performance Monitoring (APM) to monitor and manage application performance, giving a view into what parts of a transaction call chain are slowest. It is a powerful tool for monitoring call completion times and examining particular requests and transactions.
Quite beyond APM, it seems natural to expect tracing to yield a ‘troubleshooting tool to rule them all’. The detail and semantic locality of the trace, coupled with the depth of the service call graph, generate this expectation. It’s obvious that correlating across services gives diagnostic power. The typical traceview screams the sort of “first this, then that” narrative RCAs are made of.
In reality, though, users have seen mixed results. According to a prospect:
“We paid six figures for a <well-known tracing tool> contract, to reduce MTTR significantly. We’ve given up on that. We’re writing it off. Engineers had to do extra work to implement it. Operations had to do extra work to set and respond to alerts. The alerts worked well but, in the end, finding root-cause was still slow. It just wasn’t worth it.”
This is not isolated feedback.
“Tell me where to focus”
There are two issues raised: work required to yield results, and inadequacy of those results. The first issue is easy to understand: depending on the stack, the application, the application’s evolution, the deployment mechanisms and so on, it may indeed be a lot of work to generate useful traces. This problem is not surprising and can be surmounted; it is worth taking away that zero-configuration, zero-instrumentation (i.e., autonomous) solutions are of great value.
The larger issue is around applicability for root-cause detection. Here, respected Observability author and blogger Cindy Sridharan has some insightful things to say. I’ll lift a quote from her article which I highly recommend:
“What’s ideally required at the time of debugging is a tool that’ll help reduce the search space… Instead of seeing an entire trace, what I really want to be seeing is a portion of the trace where something interesting or unusual is happening… dynamically generated service topology views based on specific attributes like error rate or response time…”
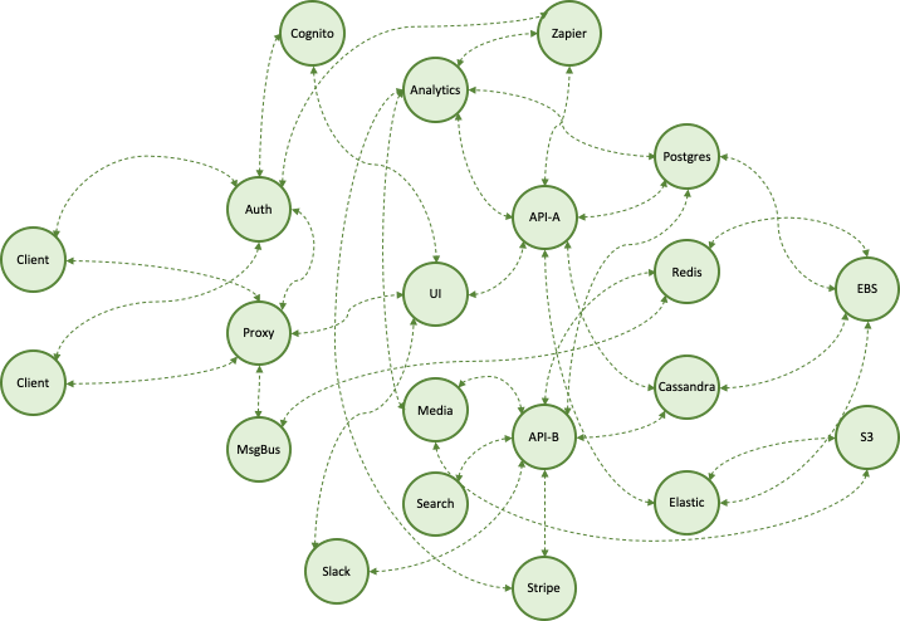
We need a tool that takes a stab at incident and, if possible, root-cause detection, or highlighting. Stepping back further, I would posit that trace data has become a bit like log data: a treasure trove of untapped information for root-cause detection, in-part because there is just too much detail to sift through without help.
Virtual tracing alone
Tracing is so promising for troubleshooting because of semantic locality. Tracing works the way it does because span ids are passed around the stack - in headers or log lines, for example. These spans are then associated together into a trace, and so we know all the spans in the trace are at least to some extent “about” the same thing - a transaction or request, for example.
There are other ways to establish semantic locality. Looking again at a trace, we might note that its spans demonstrate temporal locality, as well. We might suppose that a majority of service-impacting incidents also have temporal locality: if Service A fails, and Service B calls Service A, then Service B is likely also to fail, soon after Service A does. Our job will be to determine spans of telemetric data that share semantic locality.
Could we suppose that events happening nearby in time are semantically related? Of course not… but, we could look for features in *ordinary telemetry* - “rareness” or “badness”, for example - and model inter-occurrence intervals of such features across services. Rareness might be indicated by rare log events from a given container, for example, or a multi-hour peak in a metric; badness might be indicated by a flurry of errors from another container, or a host log.
Machine learning could observe the ordinary behavior of the system to estimate parameters for our model, and then use the model to hypothesize which features ARE semantically related, with high probability. Related features would in this way correspond to a virtual trace; each virtual span would map directly to a timespan of telemetric data capture for a single generator - host, container, or service, for example.
A virtual tracing example
A database server is inadvertently shut down. A number of rare events are emitted into its log stream; a rare spike in available memory occurs on the host(s). A few seconds later, a flurry of unusual errors are emitted in the log stream of a service reliant on the database because it cannot connect to the database.
Say, rare events in the database log stream happen at random about once per day, on average; rare errors in the consumer’s log stream happen about once every hour; comparable spikes in available memory happen twice a day. But now, all three of these rare things happened within 3 seconds.
The ML model decides these all should be part of a virtual trace, as a result; we construct spans of related activity on each generator - contiguous timespans, in fact - and bundle them up. If there was enough badness, we notify; we fingerprint to keep track of separate “trace types”. In this way we’ve achieved the goals of autonomous incident and root-cause detection; we can present only the data and services where attention should be focused.
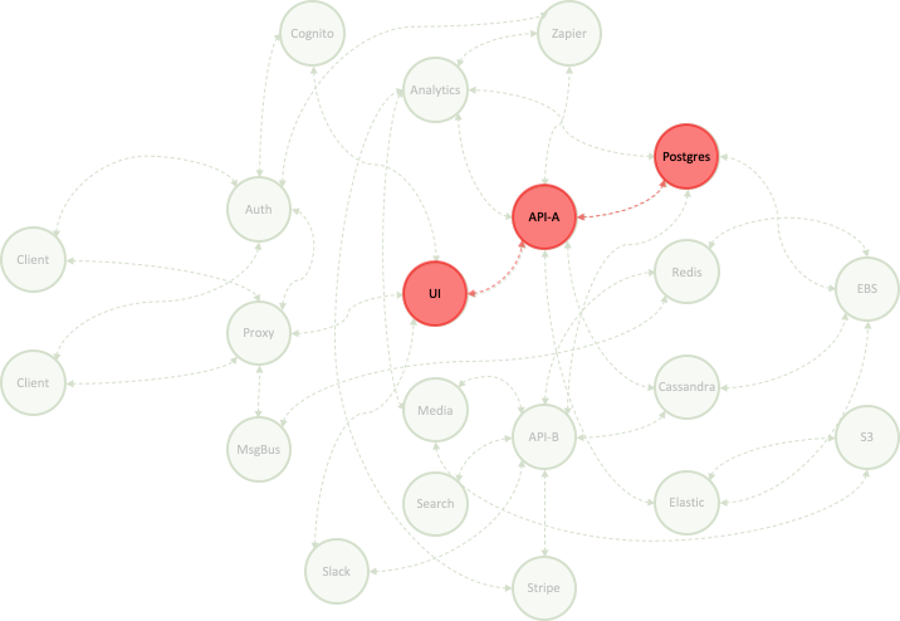
Virtual and instrumented tracing combined
Combining these approaches yields real opportunities for improving the user experience. The instrumented trace augments the virtual one. For example, the service graph can be used to exclude virtual spans from a virtual trace based on implausibility of the related generator causing the observed badness; the full trace can give deep performance context to the virtual trace and serve as a launching-off point to navigate to other services and/or similar traces. Instrumented tracing brings precision, depth, and broad context to a virtual trace.
Similarly, the virtual trace augments the instrumented one. We can hone or auto-tune our alerting based on badness seen in the virtual trace; we can hone the traceview to just those services and components touching the virtual trace, and then allow the user to expand outward, if need be. Virtual tracing brings autonomy, incident detection, and root-cause indication to an instrumented trace.
Zebrium has built an implementation of virtual tracing into its autonomous log management and monitoring platform. You can read more about it here.
