
I wanted to give you an update on my last blog on MTTR by showing you our PagerDuty Integration in action.
As I said before, you probably care a lot about Mean Time To Detect (MTTD) and Mean Time To Resolve (MTTR). You're also no doubt familiar with monitoring, incident response, war rooms and the like. Who of us hasn't been ripped out of bed or torn away from family or friends at the most inopportune times? I know firsthand from running world-class support and SRE organizations that it all boils down to two simple things: 1) all software systems have bugs and 2) It's all about how you respond. While some customers may be sympathetic to #1, without exception, all of them still expect early detection, acknowledgment of the issue, and near-immediate resolution. Oh, and it better not ever happen again!
Fast MTTD. Check!
PagerDuty is clearly a leader in Incident Response and on-call Escalation Management. There are over 300 integrations for PagerDuty to analyze digital signals from virtually any software-enabled system to detect and pinpoint issues across your ecosystem. When an Incident is created through one of these monitoring integrations, say an APM tool, PagerDuty will mobilize the right team in seconds (read: this is when you get the "page" during your daughter's 5th birthday party). Fast MTTD. Check!
But what about MTTR? By R, I mean Resolve
All great incident response platforms will have workflow and run book automation mechanisms that can help restore system operation quickly in some typical cases. But this doesn't get to the root cause so you can understand and resolve the issue and not let it happen again. For that, enter the all-too-common "War Room". That term and concept was first coined in 1901 but was probably made most famous by Winston Churchill during WWII where the Cabinet War Room was the epicenter of intelligence gathering, data analysis and communications throughout the war. Back then it was the telegraph, phones, radio signals and maps on the wall. Today it's likely a virtual room using Zoom, Slack, real-time visualizations, cell phones, and most important, logs. Millions and millions of logs! But, the prevailing attitude of the War Room has remained unchanged - "If you're going through hell, keep going".
The initial signal that triggered the incident was likely from an alert which perhaps detected that a predefined threshold was "out of tolerance", how ever simple or complex that may be. Or perhaps from an alert you defined in a ping-tool or maybe some home grown live tail watching for spikes in error counts or some similar patterns. Whatever the means, it was based on some predefined rule(s) to detect symptoms of a problem. In most cases, the next step is determining the root cause. For example, the symptom that triggered the signal might have been that latency was too high, but this tells you nothing about the root cause.
Whether you formalize a designated War Room for a particular incident or not, two things are certain: 1) timely, thorough and accurate communication between team members is paramount and 2) You’re likely going to search through logs and drill down on various metrics to get to the root cause. And this brute force searching through logs and metrics is probably your hell.
Stop going through Hell
Many monitoring tools have started to utilize various machine learning and anomaly detection techniques to raise that first signal to trigger an incident response, often via platforms like PagerDuty. However, these techniques still require too much human input to handpick which metrics to monitor, and to choose specific algorithms or tuning parameters. Anomaly detection in monitoring tools is predominately geared towards time-series data and rarely for logs. Yet logs are indispensable for root cause analysis. This makes these tools blind to the root cause of any issue and will ultimately require time-consuming drill-down and hunting through the logs. Millions and millions of logs!
By contrast, Zebrium's machine learning detects correlated anomalies and patterns in both logs and metrics and uses them to automatically catch and characterize critical incidents and show you root cause (see - The Anomaly Detection You Actually Wanted. This means faster MTTR and no more hunting for root cause! We call this Incident Recognition and its part of our Autonomous Monitoring platform.
Now, let me show you how you can tie your existing incident management workflow together with automatic root cause identification, regardless of the triggering signal – for fast incident resolution.
Augmenting detection with Zebrium automatic root cause identification
Zebrium uses unsupervised machine learning to automatically detect and correlate anomalies and patterns across both logs and metrics. These signals form the basis for automated Incident Detection and Root Cause identification.
In addition to autonomous monitoring, we can also consume external signals to inform our Incident Detection. Imagine any one of your monitoring tools in your PagerDuty ecosystem has created an Incident and you get "The Call" (at one of those inopportune moments). What happens? Well you probably already know the pain that will lie ahead. But what if instead you looked at the PagerDuty Incident or your Slack Channel and a full report of the anomalous logs and metrics surrounding the incident – including the root cause - was already there, at your fingertips.
Walkthrough: An APM triggered PagerDuty Incident gets augmented with root cause
Here's how it works:
- Your AppDynamics APM tool detects a Critical Health Rule Violation: Login Time Exceeds 60 seconds (you can see that in the PagerDuty Incident below) and sets everything in motion.
- Through an existing integration with PagerDuty, an incident is created and the escalation policy fires (the war room is now open) and you see this in PagerDuty:
AppDynamics Triggered an Incident in PagerDuty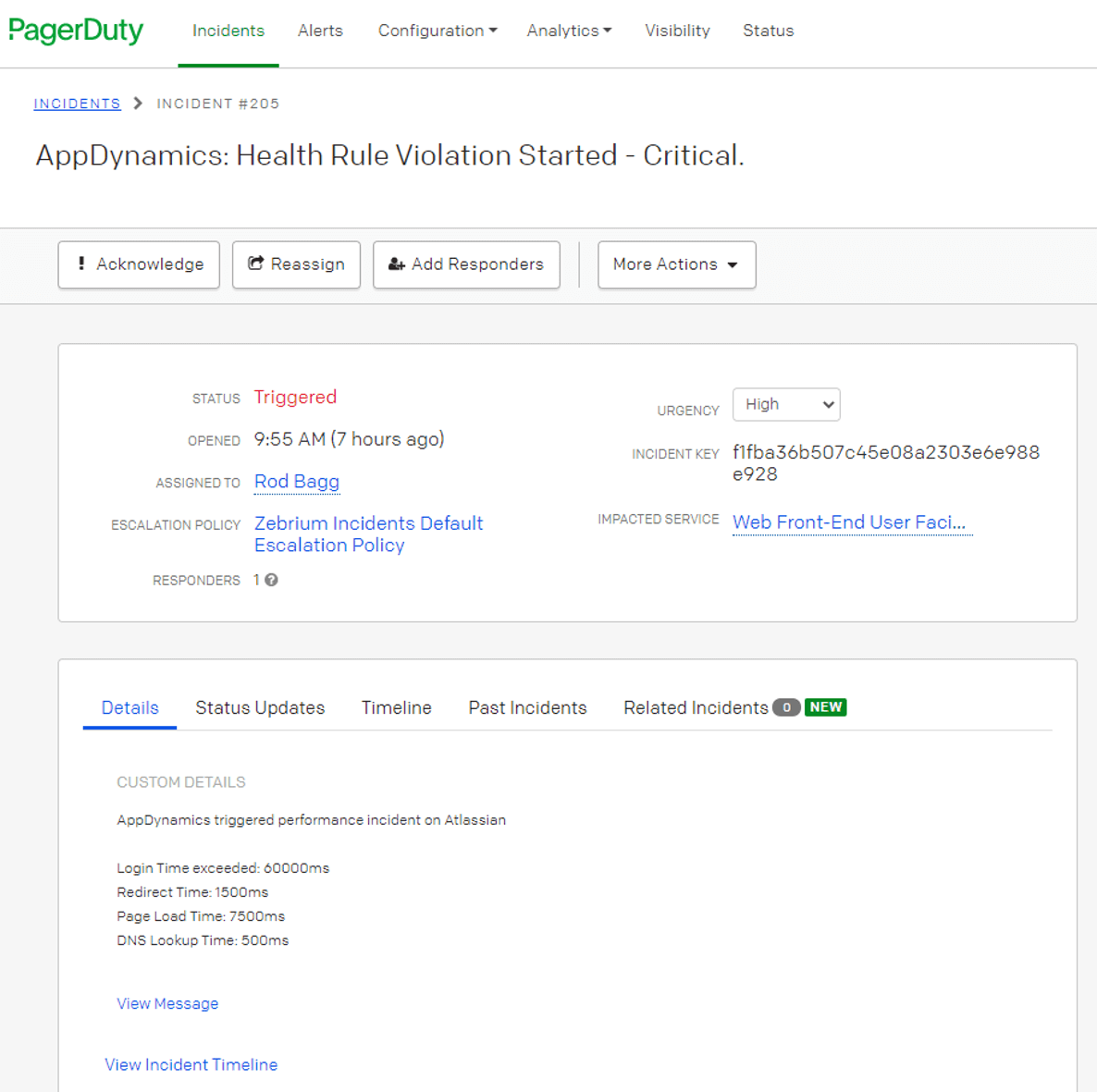
- If you also have a PagerDuty/Slack integration, you'll see something like this:
PagerDuty Notifies Slack with your AppDynamics Incident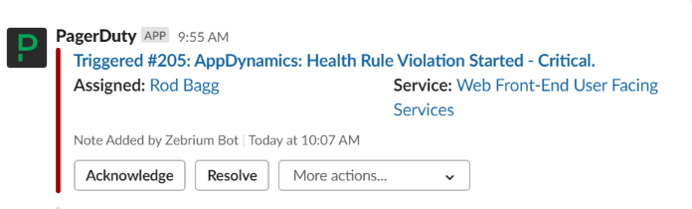
- At that same instant, PagerDuty automatically sends a signal to Zebrium with all the incident details.
- At this point, Zebrium does three things:
The first thing Zebrium does is correlate the PagerDuty incident details with its Autonomous Incident Detection and Root Cause by looking across logs and metrics over the past half hour for any Incidents it has already detected. - And in this case, Zebrium has detected what looks to be a relevant incident. The PagerDuty incident is updated with the Zebrium Incident details and likely root cause via the PagerDuty API. Here's what that PagerDuty update looks like in Slack:
Zebrium detected an Incident and Root Case and has updated PagerDuty and Slack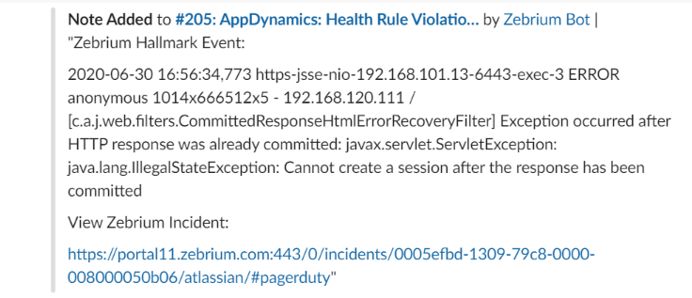
- If you need to drill down further, it's just one click from either the Slack channel or your PagerDuty Incident. Let's take a look...
Zebrium Incident Drill Down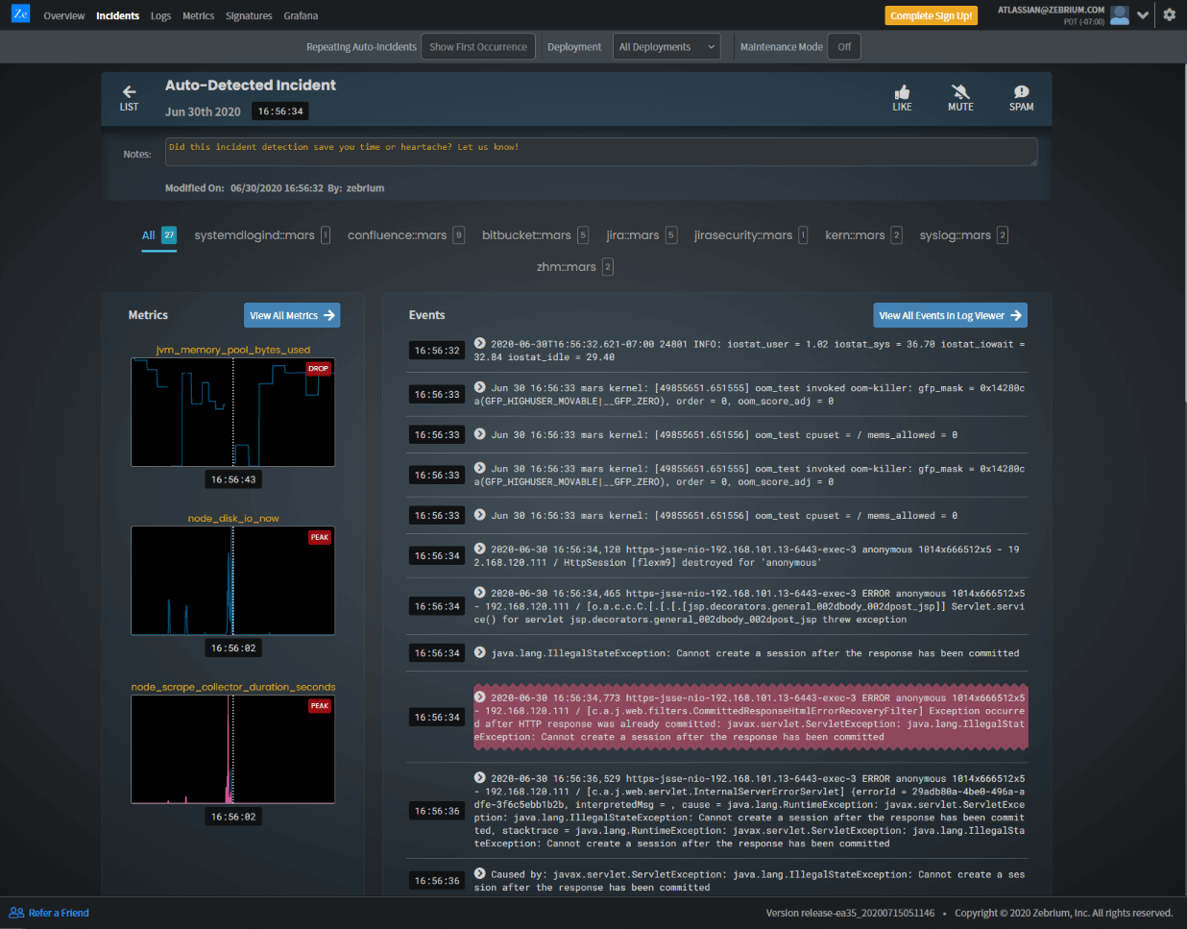
Looking at our Zebrium Incident, your attention is immediately drawn to the Hallmark event in red. This is what we believe is the most relevant and important anomalous event in the Incident. When we look closer, we see that Java "Cannot create a session". That seems very closely related to our APM alert "Login Time Exceeds 60 seconds".
At the top of the incident, we also see a correlated metric anomaly in the JVM Pool. In fact we see that drop a couple times. We might think that's the issue. But it's not a root cause.
We typically would see a root cause occurring near the beginning of a Zebrium Incident timeline. So looking up the list of events, we see the Kernel invoking the OOM-KILLER on a process called oom_test. And this is in fact the root cause. We had started oom_test to continue to consume memory until killed.
The Zerbium Autonomous Monitoring Platform identified this Incident and Root Cause completely unsupervised. There were no predefined alert rules and there was no human intervention whatsoever (other than starting the oom_test program). - The second a really cool thing Zebrium does, is it creates a Synthetic Incident. While it's very likely Zebrium has already detected the Incident and Root Cause automatically, we will additionally take the Signal from the APM Incident and create a new Zebrium Incident with any further anomalous events or metrics around the time of the signal to make sure this information is also easily at-hand. This often proves very useful to the person doing the troubleshooting. And indeed, you can see that happened and we've added a note to the PagerDuty Incident and Slack channel.
Zebrium Synthetic Incident Created and Updated in PagerDuty
- Finally, the third thing we'll do is keep an eye on things for the next thirty minutes and continue to update the PagerDuty Incident with any new Incidents we identify.
09:55 - AppDynamics detected a Health Rule Violation
09:55 - Seconds later, PagerDuty creates the Incident and signals Zebrium right away
09:55 - Less than a minute later, Zebrium has updated the PagerDuty Incident with a link to the Zebrium Incident and ultimately the Root Cause that had already been identified in the past half hour.
10:07 - Zebrium creates a Synthetic Incident with additional details and updates the PagerDuty Incident.
10:25 - Zebrium continues to watch for additional incidents for 30 minutes after the signal is received.

Summary of the Overall Workflow
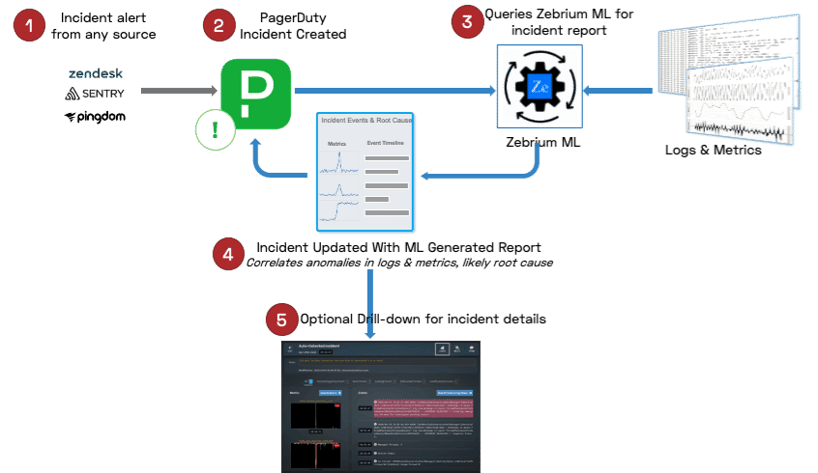
Let Zebrium take care of MTTR
Using PagerDuty, Zebrium can now augment existing incidents that have been detected by any 3rd-party tool. In doing so, your incident will be automatically updated with details of root cause without all the hunting, scrambling and adrenaline that is normally associated with a war room!
You can get started for free by visiting either https://www.zebrium.com or https://www.pagerduty.com/integrations/zebrium/.
Now that's MTTR!
