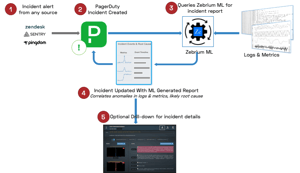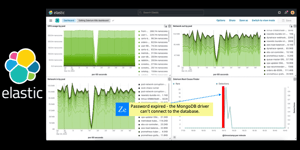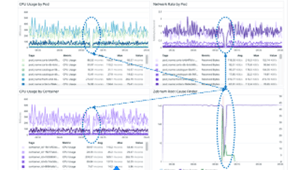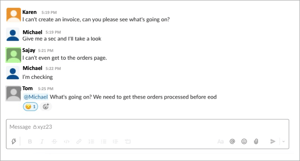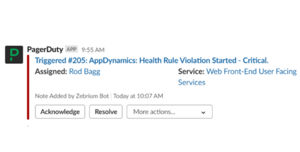
PagerDuty is a leader in Incident Response and on-call Escalation Management. There are over 300 integrations for PagerDuty to analyze digital signals from virtually any software-enabled system to detect and pinpoint issues across your ecosystem. When an Incident is created, PagerDuty will mobilize the right team in seconds (read: this is when you get the "page" during your daughter's 5th birthday party).
I wanted to give you an update on my last blog on MTTR by showing you our PagerDuty Integration in action.
As I said before, you probably care a lot about Mean Time To Detect (MTTD) and Mean Time To Resolve (MTTR). You're also no doubt familiar with monitoring, incident response, war rooms and the like. Who of us hasn't been ripped out of bed or torn away from family or friends at the most inopportune times? I know firsthand from running world-class support and SRE organizations that it all boils down to two simple things: 1) all software systems have bugs and 2) It's all about how you respond. While some customers may be sympathetic to #1, without exception, all of them still expect early detection, acknowledgment of the issue, and near-immediate resolution. Oh, and it better not ever happen again!