
When a new/unknown software problem occurs, chances are an SRE or developer will start by analyzing and searching through logs for root cause - a slow and painful process. So it's no wonder using machine learning (ML) for log analysis is getting a lot of attention.
But machine learning (ML) with logs is hard. Here's a simple example: when troubleshooting, a skilled SRE might start by looking for log events that are "rare" and "bad" (errors, exceptions, etc.), particularly if there is a cluster of such events across multiple logs. However, logs are vast, noisy and mostly unstructured. So how does the machine learning know if a particular log line is rare rather than just a different example of a an event it's seen before (remember, event types have fixed and variable parts)?
This blog discusses some of the existing methods for log analysis and anomaly detection using machine learning.
Machine learning for logs: types of ML models
Machine Learning (ML) uses statistical models to make predictions. For analyzing logs, a useful prediction might be to classify whether a particular log event, or set of events, is causing a real incident that requires attention. Another useful prediction might be to uncover an event(s) that helps to explain the root cause of an issue.
In machine learning, usually the more data available, the more accurate the ML model will be at making these predictions. This is why models typically become more accurate over time. However, when it comes to logs, this has two challenges: It leads to a long lead time to value, i.e. the system could require weeks or months of data to serve accurate predictions. Worse, slow learning ML is actually not very useful when the behavior of an application keeps changing, for example because frequent updates are being deployed for each of its microservices.
There are two main approaches for training ML models on data: supervised and unsupervised.
- Supervised training requires a labelled data set, usually produced manually by humans, to help the model understand the cause and effect of the data. For example, we may label all log events that relate to a real incident so the model will recognize that type of incident again if it sees the same log events or pattern. This can take a lot of effort, especially considering the ever-increasing list of possible failure modes with complex software services.
- Unsupervised training - In this approach, the model will try and figure out patterns and correlations in the data set by itself, which can then be used to serve predictions.
The challenge with using supervised ML with logs, is almost every environment is different. Although there might be some common services (e.g. open source components like Redis, MySQL, NGinX, etc.), there will likely also be custom applications that generate unique streams of logs and patterns. Further, even amongst common services, there are usually many different versions in common use. So this kind of machine learning would require data labeling and training in almost every environment in which it is deployed.
Given the pace of application change and the time and resources required to accurately label data and train supervised models, an unsupervised approach for logs is far more preferable. An ideal machine learning system for logs would also require only a small data set in order to achieve high accuracy, and it should also continually learn as an application evolves.
AI log analysis: existing approaches & challenges
While there have been a lot of academic papers on the subject, most approaches typically fall into two categories which are explained below:
Generalized Algorithms
This category refers to algorithms that have been designed to detect anomalous patterns in string-based data. Two popular models in this category are Linear Support Vector Machines (SVM) and Random Forrest.
SVM, for example, classifies the probability that certain words in a log line are correlated with an incident. Some words such as “error” or “unsuccessful” may correlate with an incident and receive a higher probability score than other words such as “successful” or “connected”. The combined score of the message is used to detect an issue.
Both SVM and Random Forrest models use supervised machine learning for training and require a lot of data to serve accurate predictions. As we discussed above, this makes them difficult and costly to deploy in most real-life environments.
Deep Learning
Deep learning is a very powerful form of ML, generally called Artificial Intelligence (AI). By training neural networks on large volumes of data, Deep Learning can find patterns in data, but generally is used with Supervised training using labeled datasets. AI has been used for hard problems such as image and speech recognition with great results.
One of the best academic articles on this is the Deeplog paper from the University of Utah. Their approach uses deep learning to detect anomalies in logs. Interestingly, they have also applied machine learning to parse logs into event types, which has some similarities to Zebrium’s approach discussed later, as this significantly improves the accuracy of log anomaly detection.
The challenge with this approach, is that again it requires large volumes of data to become accurate. Which means new environments will take longer before they can serve accurate predictions, and smaller environments may never produce enough data for the model to be accurate enough.
In addition, unlike the statistical algorithms discussed previously, Deep Learning can be very compute intensive to train. Many data scientists use expensive GPU instances to train their models more quickly, but at significant cost. Since we need to train the model on every unique environment individually, and continuously over time, this could be an extremely expensive way to perform automated log analysis.
Some vendors have trained deep learning algorithms on common 3rd party services (i.e. MySQL, NGinX etc.). This approach can work as it can take a large volume of publicly available datasets and error modes to train the model, and the trained model can be deployed to many users. However, as few environments are only running these 3rd party services (most also have custom software), this approach is limited to only discovering incidents in 3rd party services, and not the custom software running in the environment itself.
Log anomaly detection
Many approaches to machine learning for logs focus on detecting anomalies. There are several challenges with this:
- Log volumes are ever-growing and logs tend to be noisy and mostly unstructured. This makes log anomaly detection challenging. As described above, when troubleshooting, noticing that a rare event has occurred is usually significant. But how do you know if a log event is rare when each instance of the same event type isn't identical (event types have fixed and variable parts)? At very least, the machine learning would need to be able to categorize log events by type to know which are anomalous. The most common technique for this is Longest Common Substring (LCS), but variability of individual events of the same type makes LCS accuracy when used with logs a challenge.
- Log anomaly detection tends to produce very noisy results (this can be exacerbated by inaccurate categorization). Logs typically have many anomalies with only a few that are useful when detecting and/or troubleshooting problems. Therefore, a skilled human still needs to manually sift through and analyze the anomalies to spot the signal from the noise.
For effective ML-driven log analysis, something more is needed than just log anomaly detection.
A Different Approach to log anomaly detection
Zebrium has taken a multi-layered approach to using machine learning for log analysis - this is shown in the picture below:
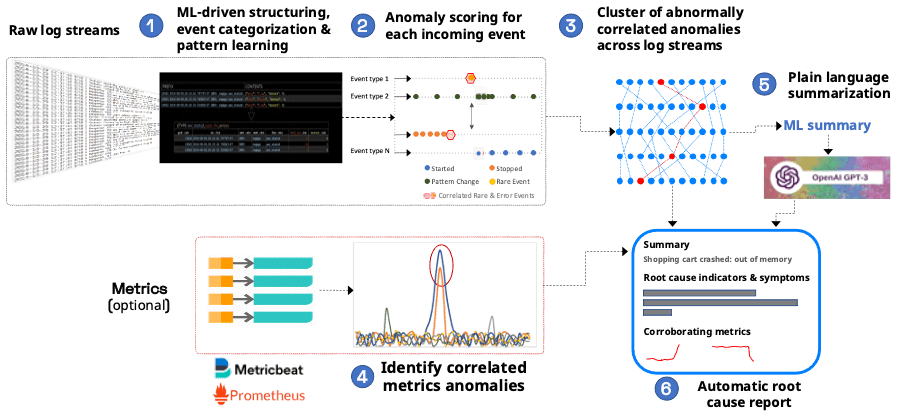
1 - Log Structuring, categorizing and pattern learning using machine learning
Unsupervised machine learning is used to automatically structure and categorize log events by type. Multiple ML techniques are used depending on how many examples of an event type have been seen. The model continues to improve with more data and adapts to changing event structures (e.g. a parameter is added to a log line), but typically achieves good accuracy within the first day. Next, the patterns for each event type are learnt. This forms the foundation for accurate ML-based log analysis.
2 - Anomaly scoring of incoming log events
As each new event is seen, it is scored based on how anomalous it is. Many factors go into anomaly scoring but two of the biggest are "how rare an event is" and its severity ("how bad an event is"). Since the categorization of log events is very accurate, so too is Zebrium's ability to detect anomalous events, but even so, log anomalies can be noisy.
3 - Finding the signal in the noise - correlated clusters of anomalies
The machine learning next looks for hotspots of abnormally correlated anomalies across log streams. This eliminates the coincidental effect of random anomalies in logs. The patterns that are uncovered form the basis of a "root cause report" and contain both root cause log line indicators and symptoms.
4 - Identify correlated metric anomalies
Since Zebrium can also optionally collect instrumented metrics, it can identify outlier metric values (metric anomalies). If there are metric anomalies that coincide with what is found in the logs, these can be used to corroborate details of what is found in the logs. The benefit of using metric anomalies in this way is that a human doesn't have to curate which metrics might be useful when troubleshooting a problem.
5 - Solving the last mile problem - using GPT-3 to summarize root cause in plain language
The Zebrium machine does a very good job of distilling details of a software problem down to just a few log lines (typically 5 to 20). A summary of this, together with the right prompt, is passed to the GPT-3 language model. The AI model returns a novel response that can be used for root cause summarization. Although this feature is designated "experimental", real-world results so far have shown that the summaries can be very useful. You can read more about it and some examples here.
6 - Delivering the results of ML-based log analysis as a root cause report
A root cause report is automatically created by combing the log lines from stage 3, with any metrics anomalies (shown as charts) found in stage 4 and a plain language summary from stage 5. The report can be delivered via webhook to another application (such as an incident response tool) or viewed interactively in the Zebrium UI.
Does log analysis with machine learning work?
The technology described above is in production and relied upon by leading companies around the world. There are two key areas where users find value:
- When you already know there's a problem - Zebrium lets you find its root cause automatically instead of manually hunting through logs. This eliminates one of the biggest bottlenecks in the incident response process. Using machine learning to uncover details of the problem means much faster Mean-Time-To-Resolution (MTTR).
- Uncover Blind Spots in Your Monitoring - Zebrium can proactively detect new or unknown problems without requiring any kind of human built rules. There are many problems that go unnoticed until they end up impacting production. Using machine learning to proactively detect these problems allows you to resolve them before they impact users.
You can read more about the Zebrium technology here, or better still, try it with your own logs.

FAQ
How does machine learning help to analyze logs?
Human-based log analysis can be slow and painful. Instead, machine learning can be used to automatically find clusters of anomalies across logs that can be used to automatically detect software problems and, more importantly, uncover root cause. This blog describes various approaches to using machine learning for log analysis.
Are there real examples for ML/AI log analysis?
The Zebrium ML/AI platform is in use across a wide variety of production environments around the world. On average it has been able to reduce software incident resolution time from hours down to minutes. Examples and case studies can be found at https://www.zebrium.com/company/customers.
How do you implement automated log analysis with Machine Learning?
Not all automated log analysis systems are the same. Traditional approaches require complex setup and take weeks or months of supervised training with large labeled data sets. Zebrium has taken a different approach. Its unsupervised machine learning can automatically find the root cause of software problems by uncovering clusters of correlated anomalies across log streams. Implementation simply requires installing a log collector (takes less than 10 minutes). The platform achieves accuracy within 24 hours.
